Most of us played with Lego as children, but I was more likely to leave lines of toy cars around the house, which is somewhat ironic given my current line of work. But I still play with Lego today, as I tidy up my children's efforts when they’re not looking.
But I think the two are linked in my line of work. I like to imagine transport models in a similar way: a number of blocks that are interconnected to produce a replica of how people and goods move around our real cities. All the way through the modelling process, from data collection to coding, model specification, software algorithms and exogenous inputs, assumptions and decisions made in one part of the model affect others.
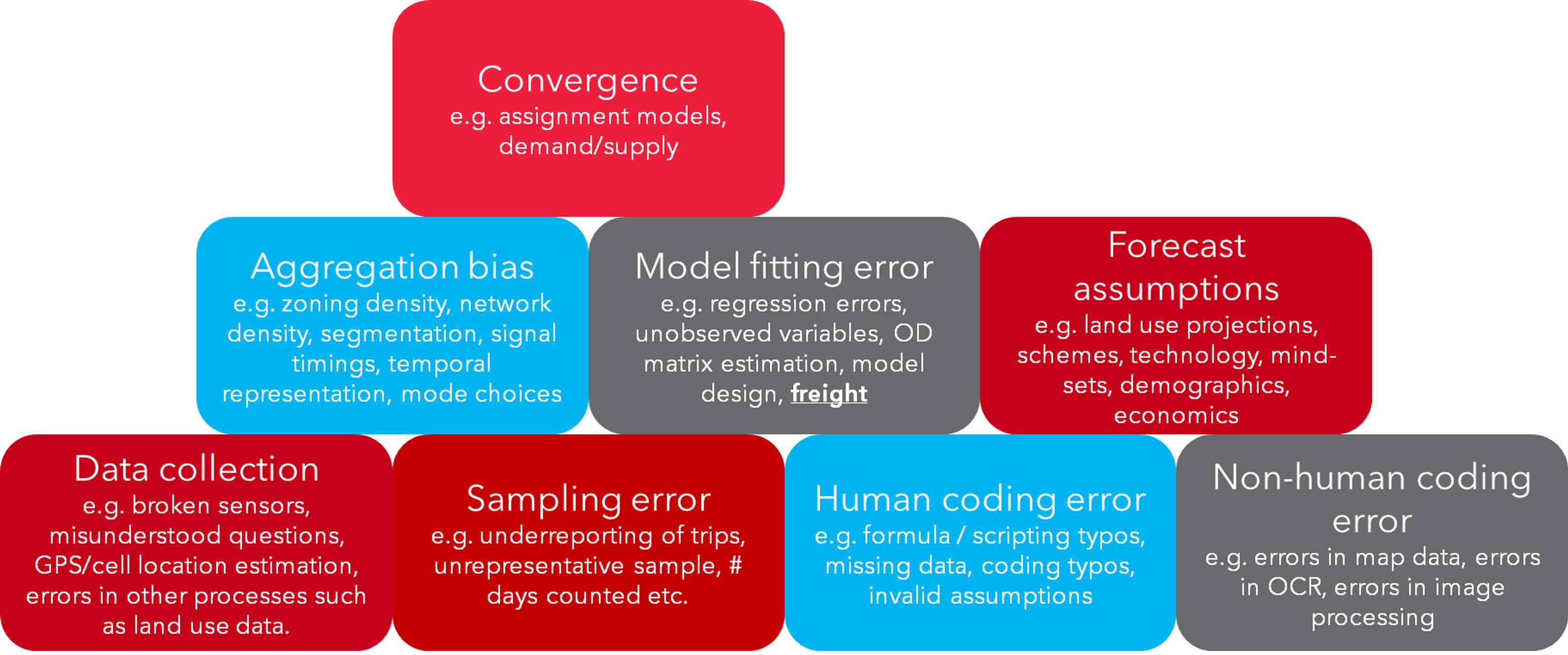
But the thing to remember is that, no matter how good your data and assumptions, there are errors and uncertainties associated with all the building blocks of a model. These errors propagate through, for example:
I would argue that while many of the errors and uncertainties identified above are reducing as our science improves and we make use of new technology and automation, some of the errors are underestimated in our industry, and are some are increasing.
Let’s be honest with ourselves. First let's take a look at data collection. In general, I think we as an industry would benefit from putting more effort in to understanding and allowing for the errors and uncertainties that arise from all aspects of data collection. However, I also believe that these errors related to data collection could overall be increasing rather than decreasing.
Mass movement data, such as mobile network data, is great because it is a huge and persistent sample. It has enormous potential to improve our modelling process. However, you must remember that there is a huge amount of processing that goes in to approximating location, modes, and in some cases, travel purpose. We should not fool ourselves in to thinking that these huge datasets create models with little effort. We still need behavioural surveys (which could of course be modernised) to fuse with mass movement data. These new datasets bring errors and uncertainties, and we need to carefully consider these and transparently allowed for them in subsequent modelling steps and application.
Now let's consider model fitting error. Data scientists will know that the ‘fit’ of any model to its training data can be improved by adding model variables, but this does not imply that the model is any better at forecasting and informing decision making. Consider this in the context of matrix estimation - we are too often using every trick in the book to squeeze out the last few percentage points in our calibration in order to tick some unnecessary box. This could at best be a waste of time, and worst be to the detriment of the quality of the model. We need to take a step back and really think about what we are doing before following the same old processes. Models need primarily to be a tool to support decision making.
Model design is a real hobby horse of mine, because I think the industry might really be doing things wrong. The UK is a fan of highway assignment models that include detailed junction modelling or simulation. I am surprised to find out that most people are unaware that there is no proof of uniqueness for this approach. This is overlooked, but means that whilst the models might ‘stabilise’, they do not finish near a single ‘optimal solution’ and any change could send the models towards a different, albeit ‘stable’ point. It is not so surprising then to hear people complain about ‘noise’ when comparing the outputs from such models.
Another big topic for me is the simplistic representation of freight traffic in our typical transport models. In urban areas, commercial transport can account for 30 per cent of the traffic, and it’s not uncommon for freight to make up 15-20 per cent of motorway traffic. This is very significant, especially considering the disproportionate impact these vehicles have on urban congestion, motorway road damage, safety, noise and emissions. Most models treat commercial traffic very simplistically, and this will significantly affect the overall quality of the outputs.
And finally, the biggest errors and uncertainties in our models comes from the forecast assumptions, those assumptions about what the future looks like, in particular with regard to the economy, society and technology.
The challenge is to get the balance right. When building and using a model, we should be addressing the greatest errors, and then running more scenarios that allow us to capture the impact of the overall errors, including their interconnectedness.
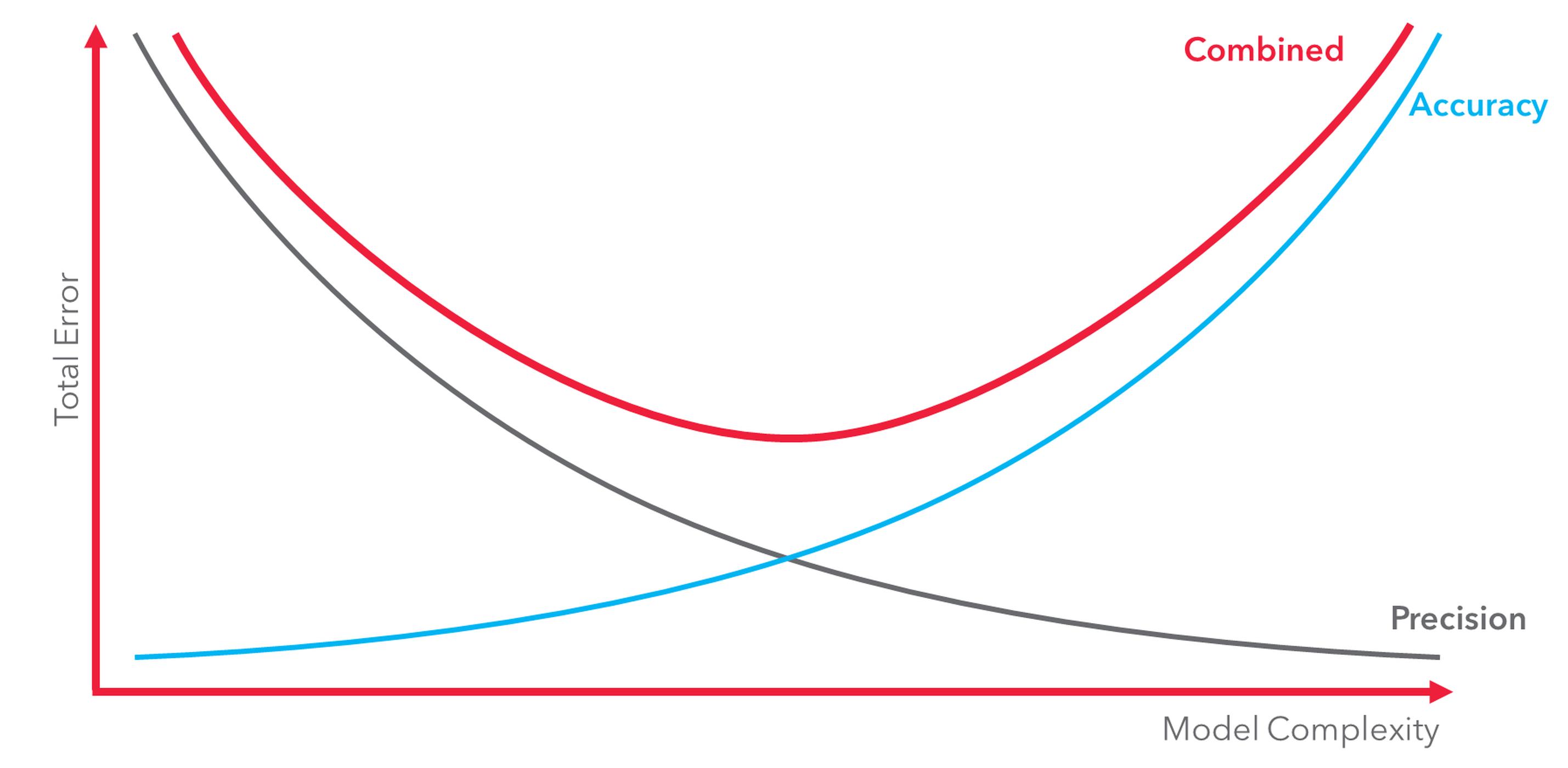
When it comes to model design, we need to appreciate that increasing model complexity can reduce model accuracy. For example, adding junction modelling increases how precisely we can represent congestion, which is a good thing. However, and conversely, it adds inaccuracy due the lack of uniqueness of such methods, imperfect stability, and we also have to decide what happens to those junctions in all future scenarios. In particular, this means we need to recalculate all signal timings. This is not only time consuming but also imprecise because many signals will be demand-actuated which cannot be represented in such ‘static’ models.
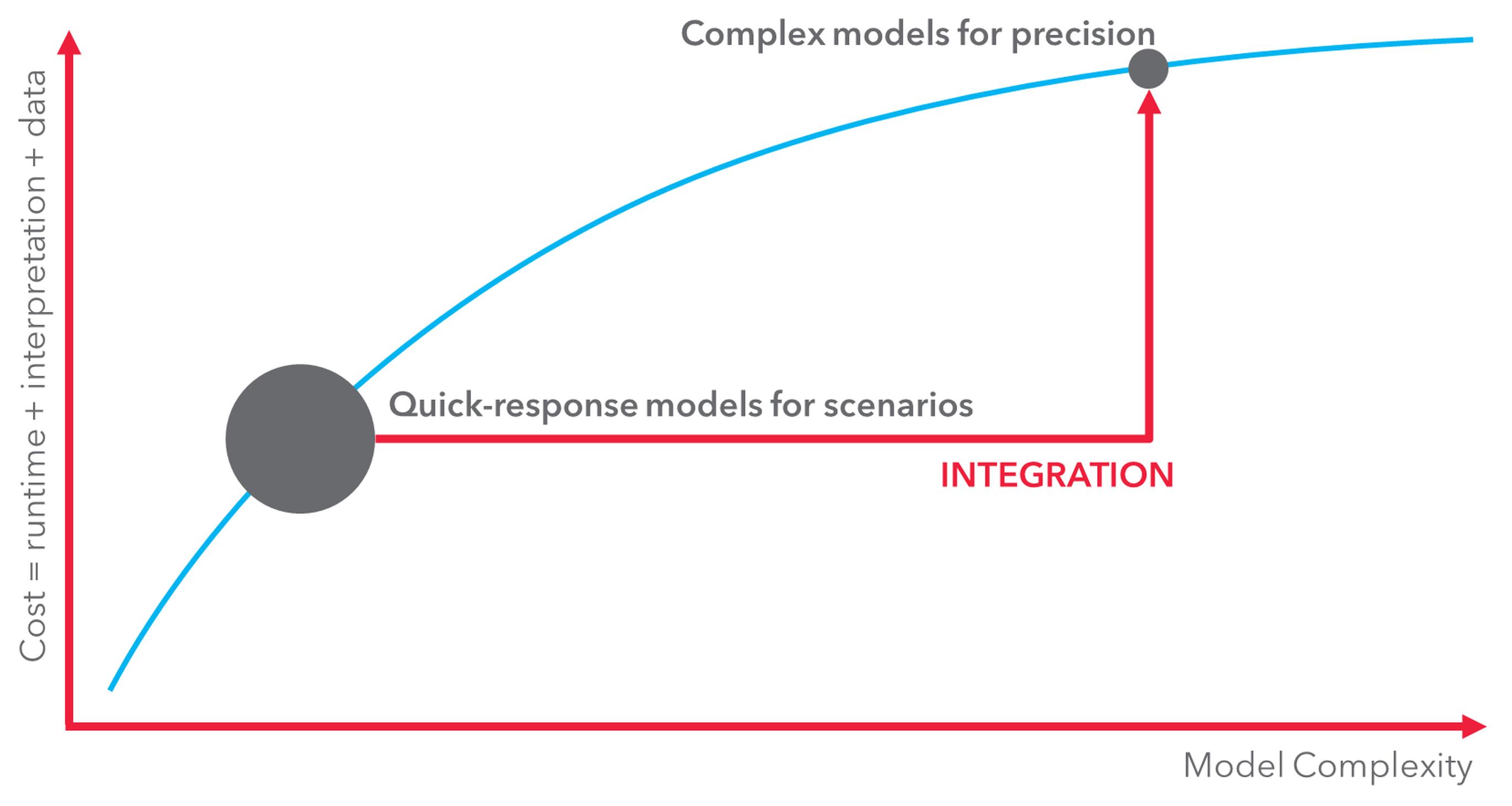
These kinds of trade-offs need to take place all through model design, before a model is built, and if the inaccuracy mitigation is not feasible or insufficient then the complexity should probably be kept out. I’m a big fan of model simplification because I think we can do a lot with a simpler model that cannot be done with a more complex one. They are faster to set up and run, and they are easier to interpret.
If designed carefully, we can create a tiered system whereby the simple and complex models can share a database. We often use the terms macroscopic, mesoscopic and microscopic in modelling. The combination of mesoscopic and microscopic modelling is already well-known. The combination of macroscopic and mesoscopic modellin – tiered macro-meso modelling –gives us the opportunity to add complexity and simplify, so getting the best of both worlds. I actually believe this is a necessary step to deal with all of the errors and uncertainties above and, in particular, the biggest one: the uncertain future.
Disruptive changes are on the horizon (e-mobility, ride-sharing, Mobility-as-a-Service platforms, CAVs), and this horizon is within the timeframe of our typical modelling forecasts. We currently do not really consider the impact of these changes in our models, and this means that decisions are being taken on the basis of models which can be (even more) wrong (than usual).
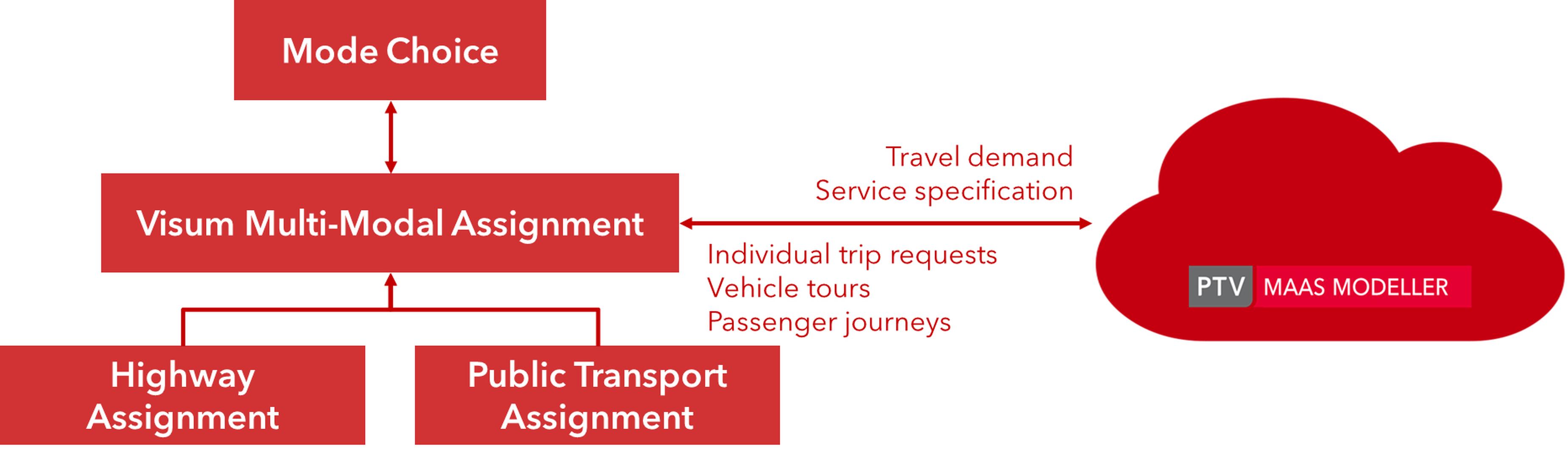
This is because reality is moving faster than modelling practice and our governance frameworks. PTV has recently developed a platform for simulating ride-sharing and connecting this to a Visum travel demand model. This removed what was arguably the main barrier from modelling disruptive futures, and now the industry needs to identify how to combine new tools like this in to the overall transport planning and modelling process.
We can provide the tools, but this doesn't address the issue that we don't know how people will react. Traditional techniques such as stated preference will not give us reliable results. Pilot studies are a more promising avenue , and should also be supported by modelling to design the test and interpret and expand the results.
This cloud of uncertainty can be intimidating. We are being challenged to disrupt our own practice. To shed light I would recommend an approach undertaken in Singapore where the Sustainable Urban Mobility Research Laboratory undertook a piece of research called 'Foresight Study on Singapore Urban Mobility'. In this study, which can be found online, the researchers used horizon scanning, stakeholder engagement and innovate workshops to identify two potential futures for further consideration: a Shared World, and a Virtual World. I recommend you explore online for further information.
What I believe we can all take from this study is so-called 'Target Forecasting'. Rather than requiring our forecasts to be constrained to some inevitably inaccurate exogenous forecasts and assumptions, we undertake scenario exploration such as used in the Singapore Study, and then identify the kinds of futures 'we' want. Models can then be used to support decision makers in how to act to move towards such a future.
Such an approach requires modelling of many more scenarios than usual, and this means we need models to be faster and easier to interpret, whilst adding in sufficient precision to represent new mobility concepts. This joins up with the earlier discussion about the need for simpler models, but we also need precision. A tiered macro-meso framework would allow for scenario exploration at the macroscopic level, and then more precise analysis to be undertaken efficiently because it is connected to the higher level.
Uncertainty about the future can actually be an opportunity to review the way we do things in all areas. It is true that uncertainty about the future is the biggest uncertainty. However, there are other very significant areas for which there are valid reasons to reduce complexity because it reduces accuracy. Likewise, there are areas which are currently far too simplistic, yet they have a disproportionate impact on model outputs. I recommend the following as a way to grasp this opportunity, take control and begin shedding light on uncertainty:
It is important to understand htat we can take control and begin shedding light on the uncertainty in models. We should be open and transparent about what can and can't be done and, if we do so, and follow the steps above, we can advance our modelling practice and support decision makers in shaping a future for the greater good. This will require some brave decisions, and acceptance of innovation by the gatekeepers. But it can be done, and it should be done.
TransportXtra is part of Landor LINKS
![]()
© 2026 TransportXtra | Landor LINKS Ltd | All Rights Reserved
Subscriptions, Magazines & Online Access Enquires
[Frequently Asked Questions]
Email: subs.ltt@landor.co.uk | Tel: +44 (0) 20 7091 7959
Shop & Accounts Enquires
Email: accounts@landor.co.uk | Tel: +44 (0) 20 7091 7855
Advertising Sales & Recruitment Enquires
Email: daniel@landor.co.uk | Tel: +44 (0) 20 7091 7861
Events & Conference Enquires
Email: conferences@landor.co.uk | Tel: +44 (0) 20 7091 7865
Press Releases & Editorial Enquires
Email: info@transportxtra.com | Tel: +44 (0) 20 7091 7875
Privacy Policy | Terms and Conditions | Advertise
Web design london by Brainiac Media 2020